



W tym poście nauczysz się zaawansowanych technik oceny i optymalizacji witryny pod kątem indeksacji i dostępności.
Oznacza to nie tylko dostępność dla wyszukiwarek, ale także dostępność dla ludzi. Dlatego ten post obejmuje najlepsze praktyki zarówno dla silników, jak i użytkowników – z tym, jak instalacja Google translate do tworzenia Ajax crawlable.
Po zastosowaniu technik w tym poście na swojej stronie internetowej, gdzie najbardziej dotyczy, powinieneś mieć wyjątkowo indeksowalną i dostępną stronę internetową.
Przeglądaj swoją stronę jak w wyszukiwarce
Optymalizując swoją stronę pod kątem SEO, czy nie miałoby sensu stawiać się w sytuacji Wyszukiwarki? I „zobacz” swoją stronę tak, jak robi to wyszukiwarka? Teraz wszyscy wiedzą, że możesz po prostu „wyświetlić źródło”, aby zobaczyć kod źródłowy HTML z dowolnej przeglądarki. Ale mam zabójczą metodę, która naprawdę postawi cię w ich sytuacji i ujawni możliwe dziury w technicznym SEO, które możesz łatwo zatkać.
Zainstaluj wtyczki
Będziesz chciał użyć do tego Firefoksa. Oto wtyczki:
-
Web Developer
https://addons.mozilla.org/en-US/firefox/addon/web-developer/
Wyłącz JavaScript w Firefoksie
Przejdź do „preferencje” i „zawartość” i odznacz „Włącz obsługę JavaScript”.
Robimy to, ponieważ elementy takie jak menu, linki i rozwijane muszą być dostępne dla Googlebota bez JavaScript. Jeśli są zakopane w Twoim JS, Google nie może ich indeksować!

Wyłącz CSS za pomocą wtyczki Web Developer
Po co wyłączać CSS? Googlebot indeksuje zawartość w kolejności HTML. Stylizacja CSS może czasami przesłaniać kolejność treści.

Ustaw User-Agent Na Googlebota

Odpal swoją stronę i przeglądaj!
Jak wygląda QuickSprout dla Googlebota?

To jest tylko góra (bo inaczej cała strona jest naprawdę długa). Ale widać, że menu pojawia się jako klikalne linki, a żaden inny tekst i linki nie są ukryte przed Googlebotem.
Zobacz swoją stronę w ten sposób, a możesz być zaskoczony, co znajdziesz!
Kilka rzeczy do sprawdzenia:
- Czy można zobaczyć wszystkie linki menu (krople też!)?
- Czy wszystkie elementy menu i linki są wyświetlane jako zwykły tekst?
- Czy wszystkie linki są klikalne?
- Czy to ujawnia jakiś tekst, który był wcześniej Ukryty? (Ukryty tekst może wysłać czerwoną flagę do Googlebota. Może nie zawsze jest tam złośliwie, ale nie powinno tam być.)
- Czy twój pasek boczny lub widżety są na samej górze? Pamiętaj, że najważniejsze linki i treść powinny znajdować się na górze HTML. Jest to ważniejsze, im większa jest strona.
Nareszcie. Oto przykład strony z problemem.

Problem z tą stroną polega na tym, że tekst menu nie jest prawdziwym tekstem, jego obrazami. Co to znaczy? Nie ma sygnału tekstowego zakotwiczenia dla Googlebota. Wszyscy wiecie, jak ważny jest tekst kotwicy dla linków zwrotnych i tak samo ważny dla linków wewnętrznych. Na powyższej stronie żadna ze stron wewnętrznych nie otrzymuje pełnej wartości linku płynącego do nich ze strony głównej.
Po wykonaniu kontroli na miejscu z punktu widzenia wyszukiwarki możesz być gotowy do indeksowania witryny za pomocą pająka sieciowego.
Indeksuj Swoją Stronę Z Krzyczącą Żabą
Co To Jest Krzycząca Żaba?
Screaming Frog SEO Spider pozwala indeksować Twoją stronę i zyskać cenny wgląd w to, jak ją połączyć o wiele łatwiej i szybciej niż kiedykolwiek mógłbyś po prostu na nią spojrzeć. Jak zobaczysz, na pewno zyskasz nowe spojrzenie na to, jak wygląda Twoja strona w ciągu najbliższych kilku minut!
Jest to praktyczny przewodnik techniczny, jeśli chcesz uzyskać więcej informacji na temat korzyści płynących z używania własnego pająka, możesz przeczytać dokumentację Screaming Frog na stronie;
http://www.screamingfrog.co.uk/seo-spider/
Uwaga: Screaming Frog jest darmowy, aby indeksować do 500 stron na raz. W przypadku większych witryn należy zakupić roczną licencję. Ale czy chcesz tajnego obejścia tego? Tak myślałem! Możesz wprowadzić podkatalogi do indeksowania https://www.quicksprout.com/2012 / da mi tylko posty z 2012 roku. Zrób to dla większej liczby podkatalogów i nadal możesz indeksować całą witrynę, tylko w kawałkach.
Indeksowanie Strony
Odpal Screaming Frog i uruchom pierwszy crawl na swojej stronie.

W zależności od wielkości witryny może to zająć od 2 do 20 minut.
Save Your Crawl
Powinieneś zapisać indeksowanie swojej witryny w .format pliku seospider. W ten sposób nie będziesz musiał ponownie uruchamiać indeksowania w przypadku zamknięcia programu lub chęci ponownego przejrzenia go później. Pamiętaj jednak, że jeśli dokonasz poważnych zmian w witrynie, i tak powinieneś ją przeszukiwać ponownie. Ale w ten sposób będziesz mieć zapis indeksowania swojej witryny od tej daty.

Sprawdź Poziomy Stron
Pamiętaj, że jest to przewodnik techniczny, dzięki któremu możesz wprowadzić prawdziwe zmiany w swojej witrynie, które przyniosą Ci zdecydowaną poprawę SEO. Skupimy się więc na pozyskiwaniu informacji z Screaming Frog, które możesz następnie zgłosić na swoją stronę.
Jeśli masz strony, które są zbyt głęboko w swojej witrynie, nie jest to dobre dla użytkowników lub SEO. Z łatwością znajdziemy te strony za pomocą Screaming Frog i umieścimy je na liście, na której możesz podjąć działania.
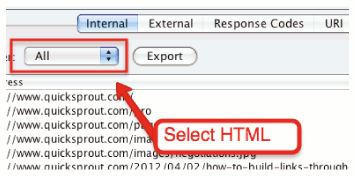
Po indeksowaniu będziesz na głównej stronie „wewnętrznej” pokazującej wszystkie dane zebrane wewnętrznie w Twojej witrynie.
- wybierz HTML

- przewiń w prawo (do końca)
- Sortuj strony według poziomu
- przewiń do tyłu
- eksport do CSV


Nawet QuickSprout ma kilka starszych postów na blogu, które zakończyły się głębokimi poziomami 4-7.
Uwaga: warto rozważyć wtyczkę do WordPressa, taką jak crosslinker https://wordpress.org/plugins/cross-linker / co może pomóc ci zawsze wewnętrznie linkować i łączyć swoje posty.
Przewiń z powrotem do lewej strony, a masz ładną listę stron z priorytetami, do których pamiętaj o linkowaniu podczas pisania nowych postów.
Teraz masz świetną, użyteczną listę adresów URL, do których można odsyłać z nowszych postów, bezpośrednio w programie Excel.
I oczywiście podczas back-linkowania, upewnij się, że odniesienia są odpowiednie, użyteczne i użyj opisowego tekstu zakotwiczenia bogatego w słowa kluczowe.
Sprawdź błędy indeksowania
Teraz zaczniemy odkrywać niektóre z różnych menu na górze. W Screaming Frog jest wiele ukrytych klejnotów, ale musisz wiedzieć, jak je znaleźć-i właśnie to wam teraz pokazuję!
Narzędzia dla webmasterów Google oczywiście dają błędy indeksowania, ale mogą być niekompletne lub stare. Dodatkowo, to da Ci wszystkie linki zewnętrzne, do których linkujesz, które są zepsute. Świeże indeksowanie witryny za pomocą własnego narzędzia to fantastyczny sposób na uzyskanie aktualnej dokładnej listy.
- Kliknij na „kody odpowiedzi”
- Wybierz „błąd klienta 4xx” z menu rozwijanego filtr
- Eksportuj jako CSV
Daje to Listę tylko stron, które zwróciły jakiś błąd poziomu 400 (Zwykle 404S).

Znajdź I Napraw Długie Tytuły
Wszyscy możecie wiedzieć, że tagi tytułu i meta opisy mają zalecaną długość. I znowu, narzędzia dla webmasterów dają Ci niektóre z tych danych.
Najlepsze w Screaming Frog jest to, że wiesz, że te dane są kompletne i możesz je sortować i filtrować.
- Kliknij na „Tytuły stron” w górnym menu.
- Wybierz „ponad 70 znaków” z menu.
- Eksportuj jako CSV


Wskazówka: natychmiast „zapisz jako” dokument Excel. W przeciwnym razie możesz stracić pewne zmiany formatowania.
W dokumencie programu Excel należy utworzyć nową kolumnę dla nowego tytułu. Ponadto Utwórz kolumnę dla długości.

Jaki prosty sposób na automatyczne liczenie znaków w programie Excel podczas komponowania nowych tagów tytułu? Dodaj ten prosty wzór do kolumny „nowa długość”; = LEN (E3)
Oczywiście pamiętaj, aby odwołać się do komórki, w której masz nowy tytuł.
A potem
- Wybierz komórkę formuły
- Najedź kursorem na prawy dolny róg komórki formuły.
- Poczekaj, aż kursor zmieni kształt na krzyż.
- Przeciągnij sguare w dół całej kolumny.
Znajdź I Napraw Długie Opisy
Znajdowanie i naprawianie długich opisów jest podobne.
Przejdziemy do menu opisów.

- Wybierz „ponad 156 znaków” z menu rozwijanego filtr
- Eksport do CSV
- Możesz pracować nad nowymi opisami, tak jak pracowaliśmy z nowymi znacznikami tytułu w programie excel. Utwórz nowe kolumny i użyj formuły = LEN (E2), aby automatycznie policzyć długość nowych znaczników opisu.
Spójrz na ustawienia indeksacji
Powinieneś również przejść do menu „meta i canonical”, aby sprawdzić ustawienia indeksacji. Powinieneś szukać takich rzeczy jak;
- Brak tagów kanonicznych
- Nieprawidłowe Tagi kanoniczne (wskazywanie na inną stronę itp.)
- Strony, które powinny być indeksowane, ale mają na sobie tag „noindex”.
- Strony, które nie powinny być indeksowane, ale nie mają metatagu lub mają „index”.

Jak znaleźć wszystkie strony z dowolnym HTML
Zróbmy coś bardziej technicznego. Załóżmy, że chcesz znaleźć wszystkie strony w witrynie internetowej, które miały obecność określonego HTML. Załóżmy, że w tym przypadku chcemy znaleźć wszystkie strony w QuickSprout, które mają linki otwierające się w nowych kartach lub oknach.
- Wybierz „Custom” z Menu „Configuration”
- Wprowadź kod HTML, którego chcesz szukać w”filtrze 1″ Uwaga: Możesz również znaleźć strony, które nie zawierają wprowadzonego kodu HTML. Możesz wprowadzić do pięciu filtrów.
- Crawl the site again
- Wybierz „Custom” w menu
- Wybierz „Filtruj jeden” z menu rozwijanego filtr.

Teraz mamy wszystkie strony z linkami, które otwierają się w nowej karcie lub oknie!
Jest to świetne rozwiązanie dla istniejącej witryny, jeśli w ogóle się nie zmieni. Ale co robisz, gdy ustawiasz się na przeprojektowanie witryny? Będziesz chciał zrobić samokontrolę w przygotowaniu do przeprojektowania.
SELF Audit for a Site Redesign
Następnie jest kompletny krok po kroku proces kontroli własnej witryny, jeśli robisz przeprojektowanie. Może to być ważny krok do podjęcia w ewolucji sieci i promowaniu swojego autorytetu w Internecie, ale nie pozwól, aby stracił na ruchu w tym procesie!
Ta część przewodnika zakłada, że stosujesz najlepsze praktyki podczas tworzenia nowej witryny, takie jak;
- Mając pewność, że jego crawlable
- Przesyłanie nowej mapy witryny XML
- Wprowadzenie 301 przekierowań
Utwórz arkusz kalkulacyjny do monitorowania postępów
Poniżej znajduje się makieta arkusza kalkulacyjnego, aby pokazać, jak monitorować te wskaźniki, gdy nowa strona będzie działać.

Monitoruj liczbę indeksowanych stron
W tym celu wystarczy skorzystać z wyszukiwarki Google: search;

Monitoruj Datę Pamięci Podręcznej
Ponownie, po prostu zrobimy wyszukiwanie w Google cache:sitename.com
Data pamięci podręcznej jest największym czynnikiem informującym, jakiej wersji witryny Google używa w swoim algorytmie.
Monitoruj PageRank
Chociaż wiadomo, że PR jest bardzo luźno używaną metryką, nadal daje przybliżone wskazanie wartości miejsca.
Użyj paska narzędzi SEOquake jako jednego z szybkich sposobów sprawdzania pagerank, który możesz zainstalować na http://www.seoquake.com/

Monitor SEOmoz Domain Authority
Ten wskaźnik będzie miał opóźnienie, w zależności od tego, kiedy SEOmoz zaktualizuje swój indeks linkscape. Ale nadal dobre do monitorowania-i można użyć ich pasek narzędzi, aby to zrobić, jak również. Możesz go zainstalować tutaj: https://moz.com/products/pro/seo-toolbar
Najlepiej patrzeć na władze DA.

Monitoruj Błędy” Nie Znaleziono”
Użyj narzędzi dla webmasterów, aby obserwować Nie znalezione błędy i uzyskać stamtąd swoje numery;
Dzięki tym narzędziom i krokom zapewnisz płynne przejście podczas przesuwania witryny.

Testowanie nowej witryny przed jej uruchomieniem
W tym samouczku skonfigurujemy komputer tak, aby po wpisaniu adresu URL przeszedł do witryny testowej, dzięki czemu można go wypróbować przed uruchomieniem przy użyciu prawdziwego adresu URL.
Uzyskaj adres IP swojej nowej strony internetowej.
Instrukcje będą się znacznie różnić w zależności od tego, gdzie hostujesz swoją witrynę, ale ogólnie rzecz biorąc, będą one wymienione gdzieś w panelu administracyjnym. Jeśli nie możesz go znaleźć, zadzwoń do firmy hostingowej i po prostu zapytaj.
Edytuj plik hosts, aby wskazać swój adres IP
-
Na Macu
- Otwórz folder aplikacji > Narzędzia > Terminal
- W aplikacji terminal wpisz „sudo nano / etc / hosts” wpisz hasło użytkownika, jeśli jest to wymagane.
- Na końcu pliku wpisz następujący wiersz: Hit Control-O to i naciśnij enter.
- Naciśnij Control-X, aby wyjść z edytora.
- Zamknij okno terminala.
- Otwórz folder aplikacji > Narzędzia > Terminal
-
Na PC
- Kliknij Start > wpisz „Notatnik” w polu wyszukiwania i poszukaj notatnika, aby pojawił się w menu start.
- Kliknij prawym przyciskiem myszy i kliknij lewym przyciskiem myszy „Uruchom jako administrator”. Powiedz Tak systemowi Windows, jeśli poprosi o pozwolenie.
- Kliknij Plik > Otwórz
- W polu Nazwa pliku wpisz ” windows system32 driver etc ” naciśnij enter.
- Zmień typ pliku rozwijany z „plik tekstowy „na”wszystkie pliki”.
- Kliknij dwukrotnie na”hosts”
- Na końcu pliku wpisz następujący wiersz:



Przetestuj swoją stronę
Otwórz przeglądarkę i przetestuj swoją stronę, aby sprawdzić, czy wygląda tak, jak się tego spodziewasz. Wpisz adres URL nowej witryny zmiany pliku hosts przekierują cię do witryny testowej.
Cofnij Zmiany
Po przetestowaniu możesz cofnąć zmiany wprowadzone w Kroku 2. Po prostu wróć do pliku i usuń właśnie utworzoną linię.
Migracja do nowej witryny bez przestojów
Ostrzeżenie: może to spowodować uszkodzenie witryny, jeśli coś pójdzie nie tak. Ostrożnie!
Podczas migracji do nowej witryny internetowej możesz skorzystać z poniższych wskazówek, aby zapewnić bezpieczne przejście bez przestojów. To trwa około dnia dla wszystkich serwerów na całym świecie, aby uzyskać zaktualizowane informacje o IP i domenie, więc zaplanuj, aby oba serwery działały przez co najmniej pierwszy tydzień nowej witryny.
Ustaw TTL nowej domeny na 5 minut
Instrukcje, aby to zrobić, są różne dla każdej firmy hostingowej lub rejestratora domen. Zazwyczaj można znaleźć to ustawienie w Panelu sterowania dla domeny, ale jeśli nie możesz go znaleźć, zadzwoń do rejestratora domeny i poproś o pomoc techniczną.
Jeśli używasz GoDaddy:
- Zaloguj się do witryny GoDaddy
- Kliknij Moje Konto. Przejdź do domen i kliknij Uruchom
- Kliknij na jedną z Twoich domen
- Przewiń w dół do Menedżera DNS i kliknij Uruchom
- Poszukaj ” @ ” pod hostem i kliknij ikonę ołówka pod „TTL”
- Pociągnij w dół menu i wybierz najkrótszy dostępny czas (1/2 godziny)



Znajdź ustawienia DNS dla swojej domeny
Po przetestowaniu witryny i zmianie TTL będziesz chciał zmienić ustawienia DNS dla nazwy domeny. Najpierw przejdź do bieżącego rejestratora domen i znajdź bieżące ustawienia DNS. Następnie przejdź do nowej firmy hostingowej i zapisz nowe ustawienia DNS, które musisz wprowadzić do obecnego rejestratora domen. Instrukcje są zawsze różne od jednej firmy hostingowej do drugiej i od jednego rejestratora domeny do drugiego.
Zazwyczaj można znaleźć to ustawienie w Panelu sterowania dla domeny, ale jeśli nie możesz go znaleźć, zadzwoń do rejestratora domeny i poproś o pomoc techniczną.
Zmień ustawienia DNS w bieżącej domenie.
Gdy masz ich obu rejestratora jako adres DNS, który zapisałeś z nowej firmy hostingowej. Powinieneś wiedzieć, gdzie je zmienić, ponieważ już go znalazłeś w kroku # 3 .
Odznacz plik hosts, usuwając linie dodane w kroku # 1.
Zrób to, wykonując krok # 1, z wyjątkiem usunięcia pierwotnie dodanych linii.
Poczekaj 5 minut,a następnie spróbuj przejść do nowej witryny.
Może być konieczne wyczyszczenie pamięci podręcznej przeglądarki i plików cookie. Jeśli twoja nowa strona jest gotowa, to gotowe! Jeśli nie, odwróć to, co zrobiłeś w kroku # 4, aby powrócić do starej witryny.
Crawlable AJAX (using jQuery GET)
W tym przykładzie pokażemy Ci, jak użyć metody post jQuery do utworzenia zindeksowanego AJAX. W tym samouczku użyjemy metody „XMLHttpRequest POST”.
Aby uzyskać dodatkowe informacje na temat tej najlepszej praktyki, przejdź tutaj: https://webmasters.googleblog.com/2011/11/get-post-and-safely-surfacing-more-of.html
Stwórz swój szablon HTML

Dodaj jQuery do swojej witryny
W tym przykładzie dodano linię 4.

Dodaj tag < DIV > z unikalnym identyfikatorem w treści, do której trafi zawartość dynamiczna
W tym przykładzie dodano linię 8.

Dodaj JavaScript do strony, która załaduje zawartość do tagu < DIV>
W tym przykładzie dodano linie 10-15.

Stwórz swój skrypt PHP
Przykładowy kod wyświetla przykładowy post na blogu.

Przetestuj swój skrypt na swoim serwerze WWW
Powinno to wyglądać tak:

Sprawdź widok-źródło
Powinien wyglądać jak szablon HTML.

Sprawdź Sprawdź Element
Powinieneś zobaczyć zawartość dynamiczną załadowaną do drzewa DOM. Powinno to wyglądać tak:

Indeksowany AJAX (bez hashów)
Ten poradnik jest dla stron internetowych, które ładują dynamiczną zawartość na stronie bez odświeżania, ale zmienia adres URL. Google zaleca przekierowanie” _escaped_fragment_ ” w ciągu zapytania do migawki HTML. Główną ideą jest to, że chcesz renderować HTML dla Googlebota i JavaScript dla użytkowników.
Istnieje wiele sposobów osiągnięcia tego samego rezultatu. Wdrożenie zależy od konfiguracji konkretnej witryny. W tym przykładzie użyjemy PHP, aby zdecydować, co renderować.
Jeśli URL wygląda tak: „
Jeśli URL wygląda tak: „
Aby uzyskać dodatkowe informacje na temat tej najlepszej praktyki, zobacz: https://developers.google.com/search/docs/ajax-crawling/docs/getting-started
Zacznij od stworzenia skryptu PHP, który doda odpowiedni tag < meta> w nagłówku
Spowoduje to poinformowanie pająków Wyszukiwania, że strona jest indeksowana za pomocą ciągu zapytania „_escaped_fragment_”. W tym przykładzie stworzyliśmy funkcję, która tworzy dla nas cały tag
.Uwaga: Linia 10 zawiera meta tag, który mówi pająkom, aby czołgali się przy użyciu fragmentu ucieczki.

Następnie stworzymy funkcję renderującą stronę
W tym przykładzie render_post ma argument ” $render_snapshot.”Domyślnie strona będzie renderować zwykłą stronę dla użytkowników. Jeśli render_snapshot ma wartość true, to renderuje zwykłą stronę HTML dla Googlebota z tą samą zawartością.
Uwagi:
- Linia 25 PHP decyduje, czy strona ma być HTML czy dynamiczna.
- Linie 26-29 pobiera zawartość i zwraca HTML wewnątrz znacznika DIV
- Linie 31-37 pobiera zawartość za pomocą jQuery do dynamicznego dodawania HTML wewnątrz tagu DIV

Następnie dodamy kod do obsługi sekwencji zapytania o fragment
W tym przykładzie, jeśli zostanie znaleziony _escaped_fragment_, post będzie renderowany za pomocą HTML.

Następnie stworzymy treść.plik php
W tym przykładzie kod przekonwertuje JSON na HTML.

Na koniec stworzymy ajax_crawling.json
Chociaż jest to tylko demonstracja, zasady nadal obowiązują w złożonej konfiguracji witryny. Treść zazwyczaj pochodzi z bazy danych. W tej demonstracji jest to tylko jeden plik.

Przetestuj stronę jako renderowaną przez użytkownika
Strona powinna wyglądać podobnie do tej:

Spójrz na źródło widoku
Nie powinieneś widzieć swojej zawartości, ponieważ jest ona dynamicznie dodawana przy użyciu JavaScript.

Zobacz Widok Inspect Elements
Powinieneś zobaczyć swoją zawartość, ponieważ Widok elementu Inspect jest tym, jak wygląda kod HTML po uruchomieniu JavaScript.

Sprawdź widok bota dodając”?_escaped_fragment_ ” na koniec adresu URL
Powinna wyglądać tak samo jak strona dynamiczna:

Sprawdź źródło widoku bota
Powinien wyglądać jak zwykły HTML bez żadnego JavaScript.

Cross Domain rel=canonical
Kiedy używać domeny krzyżowej Canonical
Jest to miejsce, gdzie wiele osób trochę się myli, więc przed dokładną implementacją techniczną, omówmy po prostu, kiedy tag powinien być użyty.
- Użyj go, gdy zawartość ze starej witryny musi zostać przeniesiona lub powielona na nową witrynę – a stary host nie zapewnia przekierowań po stronie serwera.
- Używaj go tylko wtedy, gdy zmniejszysz powielanie na miejscu w starej witrynie w jak największym stopniu.
- Jeśli zamiast tego możesz zrobić przekierowanie 301, co zapewnia preferowaną wygodę użytkownika, użyj przekierowania 301.
- Ponadto, nie należy umieszczać noindex na stronie z rel = canonical. Strona powinna być przeszukiwalna, aby odebrać przekierowanie.
- Używaj go, gdy zawartość jest taka sama na obu stronach lub z niewielkimi różnicami.
Jak Wdrożyć
Nie różni się to tak bardzo od implementacji znacznika kanonicznego regularnego.
- Przygotuj dwie strony
- Możliwość edycji kodu źródłowego na pierwszej (oryginalnej) stronie.
- Dodaj tag do sekcji starej strony, wskazującej na nową stronę; gdzie „example-page-name” to adres URL nowej strony wskazujący na nową stronę;
Szybki Przykład
Załóżmy, że chciałem przenieść Post infografiki z QuickSprout do KISSmetrics. Być może nie robiłbym tego w prawdziwym życiu, ale załóżmy, że tak, dla przykładu. Przenosimy go do:
http://blog.kissmetrics.com/5-ways-to-get-your-infographic-to-go-viral
- Infografika na QuickSprout https://www.quicksprout.com/
2012/06/11/5-sposoby-na-infografikę-To-go-viral/ - < / head>
- Ta sama infografika na KISSmetrics http://blog.kissmetrics.com/
5-ways-to-get-your-infographic-to-go-viral - Canonical wskazuje na nową stronę
Ostatnie podpowiedzi
- Niech linki są bezwzględne, a nie względne (w tym pełny http:// etc)
- Podobnie jak w przypadku 301 unikaj łańcuchów kanonicznych
- Ostatecznie jest to wskazówka dla Google, a nie absolutny kierunek, więc będziesz chciał sprawdzić indeks Google i narzędzia dla webmasterów, aby sprawdzić, czy zostały one przestrzegane.
Naprawianie Błędów Zduplikowanej Zawartości Https
Jak jestem pewien, większość z was wie, https jest protokołem, za pomocą którego bezpieczne strony są przesyłane przez world wide web. Strony takie jak koszyk, strony logowania i inne bezpieczne obszary powinny znajdować się pod adresem https. Może to jednak potencjalnie spowodować duplikację treści z powodu dodanego „s” w adresie URL.
Zazwyczaj strony https nie powinny znajdować się w indeksie. Są to zazwyczaj strony prywatne i nie mają zastosowania do zwracania ich w wynikach wyszukiwania.
Jeśli raport indeksowania lub audyt witryny powrócą jako duplikaty adresów URL https znalezionych w witrynie, należy wykonać trzy kroki, aby rozwiązać ten problem;
- Określ, które strony są indeksowane
- Zdiagnozować, dlaczego są indeksowane
- 301 przekierowań na strony, których nie powinno być
- Usuń je z indeksu, jeśli nie powinny tam być
Znajdowanie stron https, które zostały zindeksowane
Użyj tej specjalnej wyszukiwarki Google, aby znaleźć strony z witryny, które zostały zindeksowane za pomocą https;
site:yourdomain.com inurl: https
Możesz zobaczyć strona crazyegg wygląda całkowicie czyste! Z wyjątkiem tego programu Flash loader, żadne strony https nie dostały się do indeksu.

KISSmetrics. z drugiej strony jest dobrym przykładem witryny, która ma pewne https w indeksie.
Ta druga strona jest zwykłym wpisem na blogu i nie powinna znajdować się w indeksie (trzeci wynik w dół).

A te inne wskazane strony, mają być stronami https, ale nie powinny być w indeksie;

Co więc zrobić, gdy w indeksie znajdziesz Strony, których nie powinno tam być? Jak każda stara strona, której nie chcesz w indeksie, musisz dowiedzieć się, dlaczego tam trafiła!
Zdiagnozować, Dlaczego Znalazły Się W Indeksie
Użyjmy powyższego postu na blogu jako przykładu i spójrzmy na stronę.
Możesz zobaczyć Google Chrome wskazujące https jest obecny w adresie URL, ale strona nie jest Bezpieczna. To w rzeczywistości potwierdza, że strona nie powinna znajdować się w indeksie w ten sposób.

Jego prawdopodobnie w indeksie, ponieważ został połączony skądś, wewnętrznie lub zewnętrznie, więc użyjemy kilku narzędzi, aby spróbować znaleźć źródło linku.
Najpierw użyjmy krzyczącej żaby, ponieważ wiemy, że będzie to kompletny indeks witryny.
Wprowadź domenę główną witryny w Screaming Frog (ponieważ niektóre witryny, takie jak KISSmetrics. działaj na różnych subdomenach, www / blogu itp. – chcemy mieć pewność, że otrzymamy kompletny indeks całej witryny.)

Podczas skanowania witryny możesz wyszukać adres URL tej strony i poczekać, aż się pojawi.

Następnie poczekaj, aż indeksowanie zostanie zakończone i przejrzyj jego „w linkach”.

Spójrz w kolumnie „do”, aby sprawdzić, czy jakiekolwiek linki używają”https://”

W tym przypadku nie ma wewnętrznych linków wskazujących na wersję strony https://.
Jeśli zostanie znalezione łącze wewnętrzne,musisz zmienić łącza wewnętrzne i przekierować wersję https na wersję http.
Jeśli nie zostanie znaleziony link wewnętrzny, możesz być w stanie znaleźć link zewnętrzny, ale możesz nie mieć kontroli nad jego zmianą. Więc musisz 301 przekierować go do wersji http. Spowoduje to przekierowanie użytkownika i ostatecznie usunięcie / zastąpienie wersji https z indeksu.
Paginacja z rel=next
Paginacja zawsze była jednym z najtrudniejszych elementów SEO i architektury na stronie. Ale teraz Google pozwala używać rel= „next” I rel = „prev”, aby pomóc im pokazać, że masz strony należące do serii.
Podczas korzystania z CMS, takich jak WordPress, istnieje wiele wtyczek, które obsługują to za Ciebie, w tym Yoast SEO. Ale jeśli masz niestandardową witrynę lub witrynę ręcznie zakodowaną w czystym HTML, Ta sekcja pokaże, że musisz poprawić stronicowanie z tymi nowymi tagami. To całkiem proste! Ale możesz nie znaleźć najlepszego źródła w Internecie. Tutaj upewniłem się, że jest kuloodporny.
Zidentyfikuj Swoje Strony W Serii
Użyjmy Zappos jako przykładu. Oto ich Męskie Trampki strona 1.
Zidentyfikowaliśmy tę stronę jako pierwszą z serii stron, jak widać menu dla stron 2, 3, 4 itd.
Oto strona 1 URL http://www.zappos.com/mens-sneakers-athletic-shoes ~ dA
i Strona 2, 3 itd http://www.zappos.com/mens-sneakers-athletic-shoes ~ dB
http://www.zappos.com/mens-sneakers-athletic-shoes ~ dC
Uwaga: używają liter (A, b, c), aby zmienić stronę.

Add rel=”next” To Page One
To prawda, po zidentyfikowaniu stron w serii, strona pierwsza otrzymuje tylko tag „następny”, ponieważ jest to pierwsza strona w serii. Dlatego do strony pierwszej, w sekcji
dodalibyśmy;Zmień ustawienia DNS w bieżącej domenie
Każda strona oprócz pierwszej i ostatniej powinna mieć znacznik” następna „i” poprzednia”. Ma to sens, ponieważ istnieją strony przed i po. Strona druga (mens-sneakers-athletic-shoes~dB) miałaby to;
< link rel = „next”href =” http://www.zappos.com/mens-sneakers-athletic-shoes ~ dC”>
Dodaj rel= „prev” do ostatniej strony
Ostatnia strona w sekwencji musi tylko odnosić się do strony przed nią, więc dodamy;
Zakładając, że Z jest ostatnią stroną.
Uwagi Końcowe
- Możesz dołączyć tag kanoniczny w połączeniu z rel next / prev
- Możesz używać bezwzględnych lub względnych adresów URL, ale zawsze polecam absolute, jeśli to możliwe.
Przekierowanie stron błędów z .htaccess
Będzie to następować po kilku krokach;
- Utwórz stronę błędu – ta strona będzie miała specjalny skrypt.
- Skonfiguruj Swój .plik htaccess do przekierowania na stronę błędu
Utwórz Stronę Błędu
Utwórz stronę, w której błędy powrócą z – można to nazwać czymkolwiek-błędu.PHP działa.
Na tej stronie dodaj poniższy kod do góry;
switch ($_SERVER["REDIRECT_STATUS"]) {
case 400:
$title = "400 Bad Request";
$description = "żądanie nie może zostać przetworzone z powodu złej składni";
break;
case 401:
$title = "401 Unauthorized";
$description = "żądanie nie powiodło się";
break;
case 403:
$title = "403 Zakazane";
$description = "serwer odmawia odpowiedzi na żądanie";
break;
case 404:
$title = "404 Not Found";
$description = " nie można znaleźć żądanego zasobu.";
break;
case 500:
$title = "500 Internal Server Error";
$description = "wystąpił błąd, który nie pasuje do żadnego innego Komunikatu o błędzie";
break;
case 502:
$title = "502 Bad Gateway";
$description = "serwer działał jako proxy i otrzymał złe żądanie.";
break;
case 504:
$title = "504 Gateway Timeout";
$description = "serwer działał jako proxy i czas żądania się skończył.";
break;
}
?>
Ten kod PHP tworzy inny tytuł dla każdego typu błędu. W ten sposób nie potrzebujesz mnóstwa różnych plików. Robimy to wszystko w jednym pliku.
W tym przykładzie tworzymy unikalny tytuł i opis dla każdej strony błędu. Możesz jednak dodawać dodatkowe zmienne i tworzyć dowolną unikalną zawartość.
Konfiguracja .htaccess
Musisz przekierować kilka kodów błędów na stronę błędu. Powinieneś dodać następujące linie do .htaccessErrorDocument 400 / error.php
ErrorDocument 401 / error.php
ErrorDocument 403 / error.php
ErrorDocument 404 / error.php
ErrorDocument 500 / error.php
ErrorDocument 502 / error.php
ErrorDocument 504 / error.php
Optymalizacja kanałów RSS
Kanały RSS są tak ogromną częścią blogowania. Jednak czasami zapominamy, jak potężna może być optymalizacja tych kanałów! Poniższe wskazówki powinny pomóc ci w pełni wykorzystać kanał RSS.
To zakłada, że używasz feedburnera.
Zastąp domyślny kanał RSS w nagłówku
Zakładając, że korzystasz z FeedBurner, czy wszystkie linki na twojej stronie wskazują na właściwy kanał? Sekcja nagłówka strony Quick Sprout wskazuje na kanał feedburner.

Jeśli Twoja witryna tego nie robi, musisz zmienić adres URL kanału w nagłówku.plik php (jeśli korzystasz z WordPress) lub tam, gdzie pozwala na to Twój CMS.
Znajdź link RSS w nagłówku.plik php

Zastąp go swoim adresem URL FeedBurner

Szybkie Wygrane W Feedburner
Istnieje kilka prostych funkcji, które możesz łatwo aktywować w FeedBurner. Upewnijmy się, że masz je pod kontrolą!
Aktywuj SmartFeed
SmartFeed pomaga uczynić Twój feed kompatybilnym w każdym czytniku.

Kliknij Optymalizuj – > smartfeed
I aktywuj go!
Aktywuj FeedFlare
Feedflare to sposób na umieszczenie linku na dole kanału, aby poprosić użytkowników o robienie rzeczy, takich jak udostępnianie na Facebooku, e-mail, Zakładki na pyszne itp.
Jest to niezbędna konieczność dla każdego kanału RSS.
Na karcie Optymalizacja kliknij FeedFlare.
Wybierz łącza, które mają się pojawić. Feed oznacza, że pojawią się one w kanale RSS. Witryna oznacza, że pojawią się w witrynie, jeśli wyślesz kanał na witrynę.

Przycisk aktywacji jest łatwy do przeoczenia, jego dół poniżej.

Następnie dodamy kilka” osobistych ” flar. Są to proste flary, które ludzie stworzyli, które nie istnieją w domyślnym zestawie flar.
Kliknij „Przeglądaj katalog”.

Przejrzyj dostępne flary. Gdy znajdziesz taki, który Ci się podoba i chcesz go wybrać, kliknij „Link”.

Karta otworzy się wraz z flarą. Skopiuj adres URL.

Wróć do oryginalnego ekranu. Wklej adres URL flary. Kliknij „Dodaj Nową Flarę”

zobaczysz flarę powyżej. Wybierz miejsce, w którym ma być wyświetlany (kanał, witryna lub oba).

Poniżej możesz zobaczyć podgląd flar. Zmień ich kolejność, przeciągając i upuszczając elementy.

Nie zapomnij kliknąć „Zapisz”. Łatwo tam nie trafić.

Aktywuj PingShot
PingShot powiadomi usługi odczytu, gdy pojawią się aktualizacje. Przyspiesza to dostarczanie paszy.
Przejdź do Publicize > PingShot i kliknij „Aktywuj”.

Link do oryginalnego źródła paszy
Czy kiedykolwiek Twój kanał RSS był skrobany i powielany na innej stronie bez Twojej zgody? Dzieje się to cały czas, zwłaszcza, że stajesz się bardziej popularny (z pomocą tego przewodnika!). Googlebot lub użytkownicy mogą mieć trudności z określeniem, który artykuł był oryginalnym źródłem.
Dlatego dodamy link na dole Twojego kanału RSS, cytując Cię jako oryginalne źródło Twoich treści. Nie tylko pomoże to użytkownikom i silnikom dokonać tego ustalenia, ale także zapewni dodatkowe linki zwrotne.
- Dodawanie linku źródła RSS w Bloggerze
- Przejdź do Ustawienia > kanał RSS witryny
- Dodaj następujący kod:
< hr />
nazwa mojego bloga< / a>
- Dodawanie linku źródła RSS w WordPress
- Przejdź do Wygląd > edytor > funkcje.php
- Dodaj następujący kod:
function embed_rss ($content) {
if(is_feed())
$content .= "'";
$content .= get_the_title ()." < / p>;
return $ content;
}
add_filter ('the_content', 'embed_rss');
Masz teraz odniesienie do oryginalnego źródła (ty!) treści w kanałach RSS. Jak zawsze, Sprawdź swoją pracę, aby upewnić się, że została wykonana poprawnie.
Utwórz podziękowania
Niektóre personalizacja i podziękowania dla czytelników mogą przejść długą drogę. Oto jak skonfigurować prostą wiadomość w kanale.
Przejdź do Optimize > BrowserFriendly > Content Options

Kliknij „Włącz” i wprowadź osobistą wiadomość!
Czas Wiadomości RSS
Zachęcaj do otwierania Więcej z listy wiadomości e-mail RSS, kontrolując czas wysyłania.
Przejdź do Publicize > subskrypcje e-mail > opcje dostawy

Wybierz swoją strefę czasową i najlepszy czas dla odbiorców. 9am-11am jest często dobrym wyborem.
Przekierowanie WordPress RSS do Feedburner
Możesz mieć standardowy kanał RSS wbudowany w WordPress. Możesz nawet mieć subskrybentów! Za pomocą wtyczki o nazwie „Feedburner Redirect” upewnimy się, że wszystko przechodzi przez feedburner.
Wtyczkę znajdziesz tutaj – https://wordpress.org/plugins/tentbloggers-feedburner-rss-redirect-plugin/
- Zainstaluj go w swojej konfiguracji WordPress.
- Aktywuj go.

Wprowadź adres URL feedburnera w obu polach. I gotowe!
Video Sitemaps
Jeśli masz jakikolwiek film na swojej stronie lub blogu, a zwłaszcza jeśli jest oznaczony metadanymi, musisz mieć mapę witryny wideo. Dzięki temu treści wideo są zauważane, przetwarzane i indeksowane znacznie szybciej przez Google i Bing.
OPCJA A-GENEROWANIE RĘCZNE
Jeśli masz małą witrynę z tylko kilkoma filmami, a nie dodajesz ich przez cały czas, możesz łatwo wygenerować mapę witryny wideo XML ręcznie.
Po pierwsze, chcę dostarczyć szkielet szablonu struktury XML. Możesz wyciąć i wkleić szablon, a następnie dodać własne dane.
Jest to po prostu najbardziej podstawowy szablon z wymaganymi polami.
Utwórz pusty plik XML
Utwórz plik, nazwa nie ma znaczenia, ale lubię używać: sitemap_video.xml
Następnie zapisz go w katalogu głównym, na przykład: https://www.quicksprout.com/sitemap_video.xml
Jak wspomniano, nie ma znaczenia, jak go nazwiesz, a nawet gdzie go umieścisz, ale musisz to wiedzieć później, gdy przesyłasz mapę witryny do narzędzi dla webmasterów.
Wklej to do pliku XML
< urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns: video="http://www.google.com/schemas/sitemap-video/1.1">
< video: video>
< video: thumbnail_loc >
< video: title >
< video: opis >
< video: player_loc allow_embed= ” yes „autoplay=” ap = 1″>
< / video: player_loc>
< / video: video>
< / url>
< / urlset>
Wyjaśnienie powyższego kodu;

Wiele właściwości w szablonie jest opcjonalnych, ale chciałem, abyś miał całość 🙂
Pola Wymagane
- Adres URL strony
- URL pliku wideo lub Url odtwarzacza
- Tytuł
- Opis
- Miniaturka
Wypełnimy więc nasz przykładowy szablon. Na razie usunąłem wszystkie inne właściwości, więc możesz je wyraźnie zobaczyć tylko z wymaganymi elementami;
Podstawowy kod dla jednego wideo w XML Video Sitemap
< loc>https://www.quicksprout.com/videos/neil-patel-video-1.html< / loc>
< video: video>
< video: thumbnail_loc>
https://www.quicksprout.com/thumbs/thumbnail.jpg
< / video: thumbnail_loc>
< video: opis>
Ekskluzywny film z ekspertem SEO Neilem Patelem. Jazda śmieszna
ilości leadów do Twojego bloga i poznaj sekrety 7
optymalizacja współczynnika konwersji.
< / video: opis>
< video: content_loc>https://www.quicksprout.com/video.flv < / video: content_loc>
< / video: video>
< / url>
Dodawanie Dodatkowych Właściwości
Istnieje wiele dodatkowych właściwości, które możesz dodać do mapy witryny wideo, takich jak;< wideo: Czas trwania>
< video: expiration_date>
< video: ocena>
< video: view_count>
< video: publication_date>
< video: tag>
< video: tag>
< video: category>
< video: restriction>
< video: restriction>
< video: restriction>
< video: galeria_loc>
< video: galeria_loc>
< video: Cena>
< video: requires_subscription>
< video: uploader>
< video: uploader>
< wideo: platforma>
< wideo: platforma>
< wideo: platforma>
< video: live>
Dodajmy kilka z nich z powrotem do naszego przykładu, abyś mógł zobaczyć je w akcji!
< loc>https://www.quicksprout.com/videos/neil-patel-video-1.html< / loc>
< video: video>
< video: thumbnail_loc>
https://www.quicksprout.com/thumbs/thumbnail.jpg
< / video: thumbnail_loc>
< video: opis>
Ekskluzywny film z ekspertem SEO Neilem Patelem. Jazda śmieszna
ilości leadów do Twojego bloga i poznaj sekrety 7
optymalizacja współczynnika konwersji.
< / video: opis>
< video: content_loc>https://www.quicksprout.com/video.flv < / video: content_loc>
< wideo: Czas trwania>750
< video:ocena>4.1 < /video: ocena>
< video: publication_date>2012-04-01T19:20:30+08:00
< video:restriction relationship="allow">IE GB US CA
< video:requires_subscription>no
< / video: video>
< / url>
Wiele z nich powinno być oczywistych. Zawsze możesz sprawdzić dokumentację Google, aby uzyskać dalsze wyjaśnienia dotyczące wszystkich dozwolonych pól.
Prześlij swoją mapę witryny do Google Webmaster Tools
Opcja a prześlij go bezpośrednio do narzędzi dla webmasterów
Jest to preferowana metoda przesyłania dowolnej mapy witryny xml do Google.
- Zaloguj się do Webmaster Tools
- Zobacz profil na swojej stronie
- Przejdź do konfiguracji witryny – > Sitemaps
- Kliknij „Dodaj / Przetestuj mapę witryny” w prawym rogu
- Wprowadź nazwę swojej mapy witryny i naciśnij Wyślij


Opcja B Dodaj Następującą Linię Do Swoich Robotów.plik txt
Mapa strony: http://www.example.com/sitemap_video.xml
Podobnie jak w przypadku każdej mapy witryny xml, jeśli Twoje roboty.plik txt skonfigurować poprawnie, Google z znajdź i przetworzyć wideo XML sitemaps poprzez znalezienie go w robotach.txt
.hacki htaccess
Te wskazówki działają tylko wtedy, gdy twój Klient korzysta z Apache. Jeśli twój Klient korzysta z usług IIS systemu Windows, spójrz na hacki usług IIS.
- Zlokalizuj swoje .plik htaccess na twoim serwerze.(Patrz ” jak zlokalizować .htaccess na twoim serwerze”)
- Po zlokalizowaniu pliku edytuj go za pomocą edytora tekstu.Jeśli używasz systemu Windows, polecam Notatnik. Jeśli używasz komputera Mac, pobierz darmowy edytor tekstu, taki jak TextWrangler.
- W pliku htaccess zdecyduj, co chcesz zrobić, a następnie dodaj wiersz kodu:
-
Aby utworzyć własną stronę 404
Użyj „ErrorDocument” i umieść adres URL na swojej niestandardowej stronie 404 na końcu. Przykład:
ErrorDocument 404 http://www.example.com/my-custom-404-page.html
-
Aby zabezpieczyć folder hasłem
- Po pierwsze, trzeba będzie najpierw trzeba utworzyć .plik htpasswd. Najprostszym sposobem jest użycie tego narzędzia online do jego utworzenia: http://www.tools.dynamicdrive.com/password/
- Wprowadź żądaną nazwę użytkownika po lewej stronie, a hasło, które chcesz, aby ta osoba miała po prawej stronie.
- W ” ścieżce do .HTPASSWD”, umieść go w folderze, który nie jest dostępny publicznie. Zwykle bezpiecznie jest umieścić w katalogu domowym, takim jak „/ home / myusername”
- Kliknij przycisk Prześlij i umieść pobrany plik .plik htpasswd do „/ home / myusername”
- Skoro już to zrobiłeś, wpisz to w swoje .plik htaccess
AuthUserFile / home/myusername/.htpasswd
AuthName EnterPassword
AuthType Basic
require user some_users_name
Zastąp „some_users_name” nazwą użytkownika, która będzie dozwolona w tym folderze.
-
Blokowanie użytkowników według adresu IP
Wpisz te cztery linie do swojego .plik htaccess:
Order allow, deny
Od 111.222.333.444
Od 555.666.777.888
Zezwalaj ze wszystkich
W wierszach, które mówią „deny from”, zastąp przykładowe adresy IP „111.222.333.444„z prawdziwym adresem IP, który chcesz zablokować. -
Blokowanie użytkowników przez referrera
Dodaj te trzy linie do swojego .plik htaccess:
RewriteEngine On
RewriteCond % {HTTP_REFERER} somedomain.com [NC] RewriteRule .* - [F]
Jeśli chcesz zablokować więcej niż jeden odsyłający, dodaj więcej linii RewriteCond, takich jak ten:RewriteEngine On
RewriteCond % {HTTP_REFERER} somedomain.com [NC, OR] RewriteCond % {HTTP_REFERER} anotherdomain.com [NC, OR] RewriteCond % {HTTP_REFERER} 3rdDomain.com [NC] RewriteRule .* - [F]
Zauważ, że każda linijka oprócz ostatniej powinna kończyć się na „[NC, OR]“ -
Zrobić coś innego niż indeks.html być domyślną stroną.
Powiedzmy, że chcesz ” do domu.html ” jako domyślna strona. Użyj tej linii w pliku htaccess:
DirectoryIndex. do domu.html -
Do 301 przekierowanie starej domeny do nowej domeny
Dodaj te linie do pliku htaccess
RewriteEngine on
RewriteCond %{HTTP_HOST} ^olddomain.com [NC, OR] RewriteCond %{HTTP_HOST} ^www.olddomain.com [NC] RewriteRule ^(.* ) $ http://www.newdomain.com / $1 [R = 301, NC]
Zastąp „olddomain.com” z twoją starą nazwą domeny. Spowoduje to przekierowanie linków 301 ze starej domeny do Nowej z WWW przed nią. -
Aby uniemożliwić komuś Hotlinkowanie zasobów w Twojej witrynie
Dodaj te linie do pliku htaccess
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER}! ^http://(www.)?mydomain.com/. * $ [NC] RewriteRule .(gif|jpg|js / css)$ - [F]
Zastąp mydomain.com z nazwą domeny. Linie te uniemożliwią komuś gorące łączenie plików GIF, JPG, JS i CSS. -
Aby przekierować wszystkie strony z HTTPS: / / do HTTP://
Dodaj te linie do pliku htaccess
RewriteEngine on
RewriteCond %{SERVER_PORT} !^80$
RewriteRule ^(.* ) $ https://www.domain.com / $1 [NC, R=301, L]
Zastąp domain.com z własną domeną. -
Aby przekierować wszystkie strony z HTTP: / / do HTTPS://
Dodaj te linie do pliku htaccess
RewriteEngine on
RewriteCond %{SERVER_PORT} !^443$
RewriteRule ^(.* ) $ http://www.domain.com / $1 [NC, R=301, L]
Zastąp domain.com z własną domeną. -
Aby przekierować jeden adres URL z HTTPS: / / do HTTP://
Załóżmy, że adres URL jest http://www.domain.com/mypage.html
RewriteEngine on
RewriteCond %{HTTP_HOST} !^80$
RewriteCond %{HTTP_HOST} ^www.domain.com/mypage.html [NC] RewriteRule ^(.* ) $ http://www.domain.com/mypage.html [NC, R=301, L]
-
Wykrywanie Googlebota
Może być wiele powodów, dla których chcesz wykryć Googlebota jako agenta użytkownika. Można je pozostawić wyobraźni 🙂
- Wytnij i wklej następujący kod w dowolnym miejscu < body > dokumentu:
if(strstr(strtolower($_SERVER['HTTP_USER_AGENT']), "googlebot"))
{
// co robić
} - Zastąp swoim contentReplace „/ / co zrobić ” z tym, co chcesz zrobić.Tip: Aby to HTMLZrób to.;
if(strstr(strtolower($_SERVER['HTTP_USER_AGENT']), "googlebot"))
{?>
umieść tutaj swój HTML< / H1>
< P > wszystko co normalnie byś zrobił
}
Podzielmy każdy fragment PHP.if (warunek){}– to jest po prostu prosta funkcja, która mówi „Jeśli X jest prawdziwe, zrób y”.Teraz będziemy pracować od wewnątrz zagnieżdżonego Oświadczenia.
"HTTP_USER_AGENT"– wyodrębnia łańcuch ID specyficzny dla przeglądarki$_SERVER– jest to tablica z informacjami takimi jak nagłówki, ścieżki i lokalizacje skryptów, która jest tworzona przez serwer WWWstrtolower– zwraca łańcuch ze wszystkimi literami alfabetycznymi zamienionymi na małe litery.strstr– zwraca część łańcucha haystack począwszy od pierwszego wystąpienia igły włącznie aż do końca haystack
{
// co robić
}
ukośniki do przodu / / służą tylko do komentowania. Mówimy tylko o umieszczeniu wszystkiego, co chcesz, między nawiasami klamrowymi.Jeśli bardziej lubisz wizualizacje – to jest dobre wyjaśnienie fragmentów kodu;

Dodaj własną wyszukiwarkę do swojej witryny
Niestandardowe wyszukiwanie Google w Twojej witrynie może być potężną funkcją, ale nadal wiele osób z niej nie korzysta. Przeprowadzę Cię przez etapy instalacji na twojej stronie.
Idź do – https://cse.google.com/cse/
Skomponuj tytuł i opis

Dodaj strony do wyszukiwania
Tutaj stosuje się trochę technicznej wiedzy.

Nie możesz po prostu dodać adresu URL witryny-musisz podać gwiazdkę ( * ) po adresie URL, aby przeszukiwać całą witrynę, w ten sposób;
https://www.quicksprout.com/*
Wybierz edycję i potwierdź

Po tym wszystkim mamy możliwość wypróbowania niestandardowej Wyszukiwarki przed zainstalowaniem jej na naszej stronie.
Sprawdźmy to.

Wyszukiwanie [twitter tips] w naszym niestandardowym silniku pokazuje dobre wyniki i różnorodność wśród stron w silniku. (Uwaga reklamy będą obecne, chyba że zapłacisz za wersję premium).
Teraz nadszedł czas, aby zainstalować w swojej witrynie!
Instalowanie Niestandardowego Wyszukiwania W Twojej Witrynie
Ten typ instalacji będzie albo nową stroną, albo nowym postem. Użyjmy nowej strony w tym przykładzie, jednak nowy post będzie działał w ten sam sposób.
- Przejdź do „nowej strony”
- Edycja w trybie HTMLBędziemy edytować w trybie HTML, ponieważ będziemy wklejać kod JavaScript do strony.
- Wklej Kod
- Obejrzyjmy go

 Będziemy edytować w trybie HTML, ponieważ będziemy wklejać kod JavaScript do strony.
Będziemy edytować w trybie HTML, ponieważ będziemy wklejać kod JavaScript do strony.

Blokowanie potencjalnie szkodliwych lub szkodliwych linków do witryny
Czasami haker lub nawet ktoś niedoświadczony bez złośliwego zamiaru wyśle link zwrotny do twojej witryny z parametrem zapytania dołączonym na jej końcu. Może to wyglądać mniej więcej tak:
Rozwijaj swój biznes-Quick Sprout
(Proszę nie Linkuj do mnie ani do nikogo takiego)
A złośliwy ciąg zapytania może skończyć się na różnych stronach:
- https://www.quicksprout.com/page/2/?neilpatelscam
- https://www.quicksprout.com/page/3/?neilpatelscam
Strony te mogą być indeksowane jako takie i mogą potencjalnie zastąpić prawdziwe strony w ich indeksie. Jest to mało prawdopodobne, ale w obu przypadkach może być potrzebny sposób, aby to naprawić, jeśli tak się stanie. Tu jest trochę .kod htaccess, aby to zrobić:# FIX BAD LINKS
< ifModule mod_rewrite.c>
RewriteCond % {QUERY_STRING} querystring [NC]
RewriteRule .* http://example.com / $1? [R = 301, L]
< / ifModule>
Po prostu wykonaj następujące czynności:
- Upewnij się, że.htaccess znajduje się w katalogu głównym.
- Umieść ten kawałek kodu na dole .plik htaccess.
- Zamień „querystring” na używane złośliwe querystring.
- Zastąp example.com z adresem URL Twojej witryny
- Aby dodać wiele zapytań, użyj „pipes” ( | ) jako wyrażenia „lub”: (neilpatelscam|quicksproutripoff|badblogger) dla zapytania.
- Na koniec uruchom zapytanie site: query w Google tydzień lub dwa później, takie jak: site:quicksprout.com/?neilpatelscam aby sprawdzić, czy zostały usunięte z indeksu.
Wtyczki przeglądarki do analizy na miejscu
Wtyczki przeglądarki mogą znacznie przyspieszyć przepływ pracy i wydajność. Pokażę Ci kilka wtyczek do Google Chrome i trochę o tym, jak z nich korzystać w bardziej zaawansowany sposób.
Ta sekcja wtyczek przeglądarki obraca się wokół tych, które pomagają zoptymalizować dostępność i indeksację witryn.
Po pierwsze, oto lista.
- Broken Link Checker https://chrome.google.com/webstore/detail/check-my-links/ojkcdipcgfaekbeaelaapakgnjflfglf
- Web Developer https://chrispederick.com/work/web-developer/
- Redirect Path Checker https://chrome.google.com/webstore/detail/redirect-path/aomidfkchockcldhbkggjokdkkebmdll
- Debugger Google Analytics https://chrome.google.com/webstore/detail/jnkmfdileelhofjcijamephohjechhna
- Mikroformaty do chromowania https://chrome.google.com/webstore/detail/oalbifknmclbnmjlljdemhjjlkmppjjl
Pokażę wam, jak używać niektórych z nich w zaawansowany sposób.
Broken Links Checker
Narzędzie do sprawdzania uszkodzonych linków jest nie tylko świetną wtyczką do szybkiego znajdowania uszkodzonych linków w Twojej witrynie, ale możesz go używać w kreatywny sposób na stronach innych osób, aby uzyskać pomysły na budowanie linków i poszukiwania.
Na przykład spróbuj uruchomić go na mapie witryny konkurenta. Oto jak:
- Znajdź konkurenta z mapą HTML. W tym przykładzie użyję losowo www.bizchair.com a ich mapa jest https://www.bizchair.com/site-map
- Uruchom sprawdzanie linków
- Kliknij ikonę rozszerzenia
- Poczekaj, aż znajdzie uszkodzone linki – w tym przypadku jest ich sporo.

Narzędzie do sprawdzania uszkodzonych linków jest nie tylko świetną wtyczką do szybkiego znajdowania uszkodzonych linków w Twojej witrynie, ale możesz go używać w kreatywny sposób na stronach innych osób, aby uzyskać pomysły na budowanie linków i poszukiwania.

Chrome Sniffer
Ta wtyczka automatycznie pokazuje CMS lub bibliotekę skryptów, z których korzysta strona internetowa. Niezwykle przydatny, jeśli chcesz dotrzeć do tylko właścicieli witryn WordPress, na przykład.
Podczas przeglądania Internetu ikona po prawej stronie adresu URL zmieni się tak, aby pasowała do używanego systemu CMS lub biblioteki.
Na przykład, możesz zobaczyć, że moja strona jest zbudowana na WordPress i tutaj jest strona zbudowana z Drupal.


Redirect Path Checker
Ta wtyczka automatycznie powiadomi Cię, jeśli zostałeś przeniesiony na stronę za pośrednictwem jakiegokolwiek przekierowania. Może być bardzo przydatny podczas przeglądania witryny, w przypadku, gdy wewnętrznie łączysz się z nieaktualnymi adresami URL(lub zewnętrznie)
Na przykład, Właśnie znalazłem na mojej stronie ten link do przekierowań Gizmodo 302:

Skąd wiedziałem? Ponieważ wtyczka zaalarmowała mnie o 302.

Następnie możesz kliknąć ikonę, a pokaże Ci przekierowanie (lub serię przekierowań), które przeglądarka wzięła, aby dostać się na stronę.

Pasek Narzędzi I Wtyczka SEOmoz
Możesz zrobić wiele rzeczy za pomocą wtyczki Moz. Kilka bardziej zaawansowanych rzeczy, których możesz użyć do wyszukiwania, to:
- Szybkie znajdowanie linków obserwowanych vs nofollowed
- Lub znalezienie kraju i adresu IP na stronie internetowej


Wniosek
Dobra robota!
Udało Ci się!
Skorzystaj z tych wszystkich wskazówek, aby zapewnić optymalną indeksację i dostępność, a szybko zobaczysz ogromne ulepszenia.